BGET [0][0] is a simple heap allocator used in OP-TEE [0][0][0]. It is simpler than glibc’s allocator, but some interesting quirks, which might make exploitation interesting. Today, we will look into the inner workings of BGET.
This content already is almost a year old, and refers to OP-TEE 3.6.0 – right now, they are at 3.10.0, and so some things might have changed.
OP-TEE’s Heap Allocator BGET
To determine the location of buffers allocated on OP-TEE’s heap, it is necessary to analyze the heap allocator: OP-TEE uses the BGET heap allocator both inside TAs and the TEE kernel itself. BGET can be flexibly configured to suit different environments by the use of preprocessor macros during the build process. OP-TEE chose to use BGET with two heaps per TA instance: one for the TA, and one for the LDELF loader each. The kernel has its own heap, which is also implemented using BGET. The heap only uses a preallocated memory range, which is not dynamically extended. The heap returns blocks aligned to 16 bytes, and uses a first fit strategy.
Despite availability of a such feature in BGET, heap memory is not wiped when released, potentially leaving secrets in memory. Instead, as specified in the GlobalPlatform API, OP-TEE implements TEE_Malloc to return zero-initialized memory, which is also used in the official TA code examples. In the kernel and libraries, calloc is often used by OP-TEE instead. However, the availability of the usual malloc call might cause developers not to use these zero-initialization mechanisms.
BGET contains assertions, which can be disabled by defining the NDEBUG (no debug) macro. In the kernel, this macro will be defined if CFG_TEE_CORE_DEBUG has not defined, which can be expected for production environments. In the TA SDK, this macro is never defined by default, but assertions might be disabled by a TA developer by recompiling the libutils library for performance reasons.
BGET Data Structures
In Linux environments, the GLIBC heap allocator is well-known, including techniques to exploit incorrect use of its functions unsortedbinattack. For an easier understanding of the applicability of exploits to BGET, it can be useful to compare its inner workings with GLIBC. The layout of the data structures can be seen here, showing the layout of BGET’s free blocks, comparable with chunks as called in the context of the GLIBC allocator.
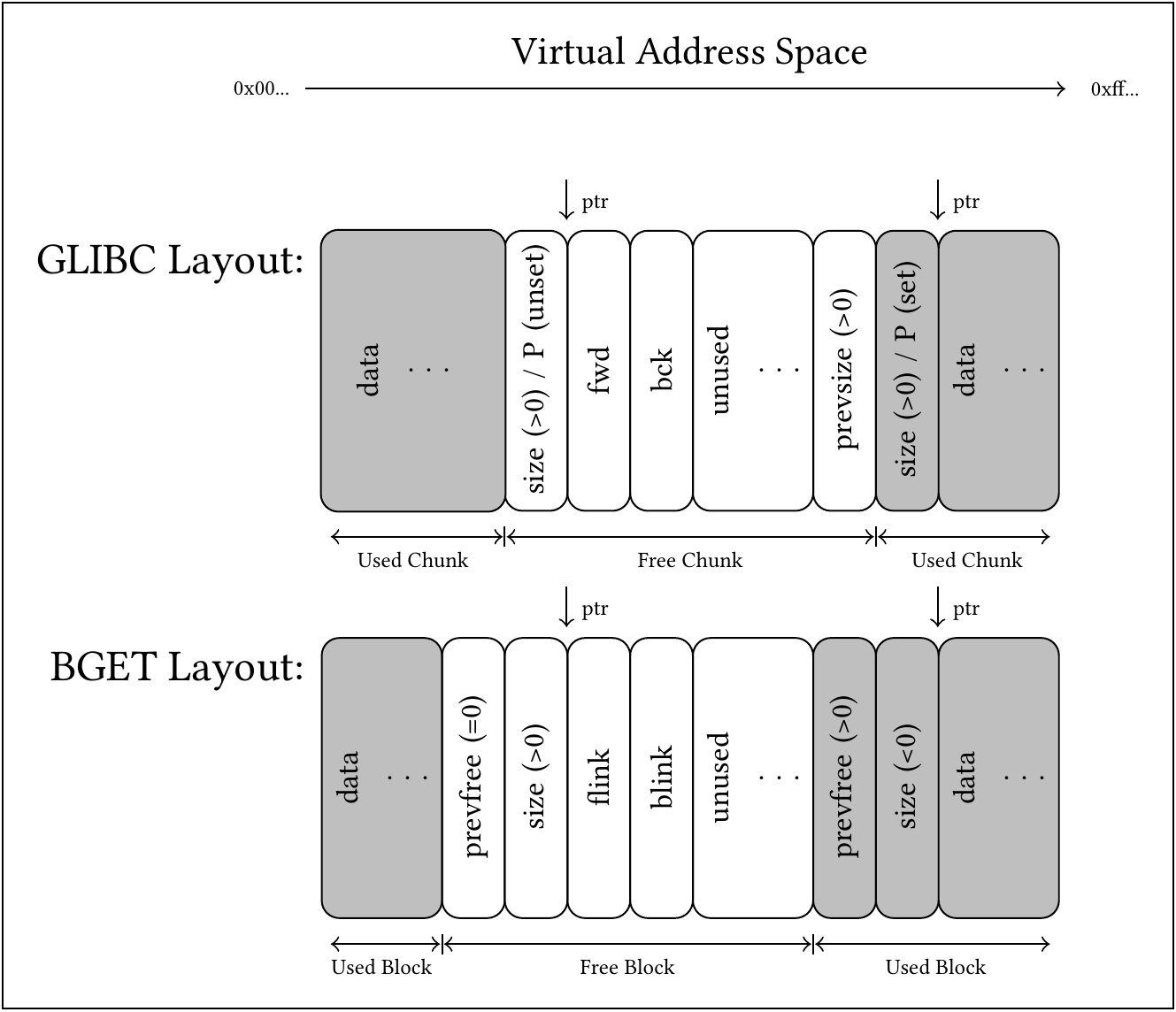 (Comparison of heap data structures of GLIBC versus BGET. Gray blocks represent data associated with a memory block in use. ptr represents current or former pointers as returned by malloc and passed to free.)
(Comparison of heap data structures of GLIBC versus BGET. Gray blocks represent data associated with a memory block in use. ptr represents current or former pointers as returned by malloc and passed to free.)
Both heap allocators track unused memory blocks within linked lists (freelist) stored within these blocks, and keep additional information to be able to determine the position of neighboring unused blocks, which enables them to merge multiple smaller unused blocks into a larger one. Both heap allocators store headers at a constant offset directly below the pointer exposed to the application developer.
While BGET only uses one allocation strategy and one freelist, the GLIBC allocator uses multiple freelists with differing semantics of the data stored therein. The most comparable freelist of the GLIBC allocator is the Unsorted Bin which, as BGET, uses only one doubly linked list to keep track of the free memory blocks, both allocators storing the links to the next and previous list element within the space the data has occupied previously. [0]
One notable difference is the metadata stored for allocated blocks. The GLIBC allocator uses the three low-order bits to encode further information, two bits being used for multithreaded memory management and uses of mmap for large allocations, and the remaining bit used as a bit flag P to encode whether the previous block is in use. This allows the GLIBC to store the size of unused blocks at their end, within the memory previously used for data, and omit these eight bytes within full blocks. Although the lowermost bit of a BGET size field can never be used due to a minimum size required to store the linked list pointers, BGET does not use this bit to encode this information. Instead, the BGET header always sets the field for the size of the previous block to zero, if it is in use.
Further, while the GLIBC allocator does not keep any information about whether a block itself is currently in use within that block, BGET uses two’s complement to encode usage of blocks with a negative size, also implicitly considering any allocation length to be a signed long integer. This additional information however is not suitable to reliably detect double-free situations, since the memory might have been overwritten meanwhile. Also, for additional assertions, both allocators additionally have the option of checking whether the metadata of the following block marks the previous one as free, which BGET does within an assertion. Notably, the size field is even checked by BGET when assertions are turned off, but only sets an unused variable as a consequence, likely to be optimized out by the compiler, and in neither case having any impact whatsoever.
Allocation Strategy
For allocations, the GLIB allocator holds a top chunk, representing untouched memory, which is only used if no other memory is available. In before the GLIBC allocator tries to find a suitable free block within multiple freelists: First, a thread-local cache (tcache) of a few hundred elements is searched for an exact match, then it uses stack-like LIFO-behaviour for small allocations, queue-like FIFO-behaviour for medium-sized allocations, and size-dependent order for large allocations. These list structures are present multiple times for similarly sized memory blocks, resulting over a hundred lists. This strategy optimized for reuse of appropriately sized blocks is likely to reuse memory already used inbefore for further allocations.
In contrary, BGET uses a queue-like FIFO-behaviour for its only freelist, which contains the block of untouched memory as its first element. Since this element can be shrunk and merged without being removed from the queue as its first element, any allocation will be placed in this block of memory, until it has completely been used once.
Operations
Allocation
Within a sufficiently large free block chosen by the allocation strategy, usually resulting in the initial block of memory, newly allocated buffers are placed at the end of this block, splitting it into two. This allows to avoid any list operations when buffers in neighboring blocks are freed in the reverse order of allocation. The block is only removed from the freelist upon exhaustion of the block, if there would be less than 32 bytes of space remaining after a split.
Necessary padding to ensure the correct 16 byte alignment of both the heap management structures and the data pointer itself is placed between the data and the block above. Additional remaining space due to incomplete exhaustion is added to the padding.
Apart from the newly allocated block’s own data structures, the prevfree field of the following block is set to zero. Further, either the size of the shrunk block is updated, or the exhausted block is unlinked from its position in the list, linking the previous and next list item with each other. The original pointers can then be overwritten with data by the application developer.
Oversized allocations exceeding 2^63 bytes will be prevented by the wrapper using the GCC function __builtin_add_overflow where the signedness is converted, which can handle differing types within a single call, and will correctly signal an overflow upon assignment to the signed type.
Deallocation
Upon deallocation, contiguous free blocks are merged immediately, never allowing multiple free blocks to occur next to each other. First, the block is either merged into an existing free block below, which keeps its position in the freelist, or it is appended to the end of the freelist as a new element. Then, a free block above, if present, is unlinked from the freelist and merged into the expanded or new list item by further expansion. Two of the four possible situations, showing no merges and both merges, are visualized here:
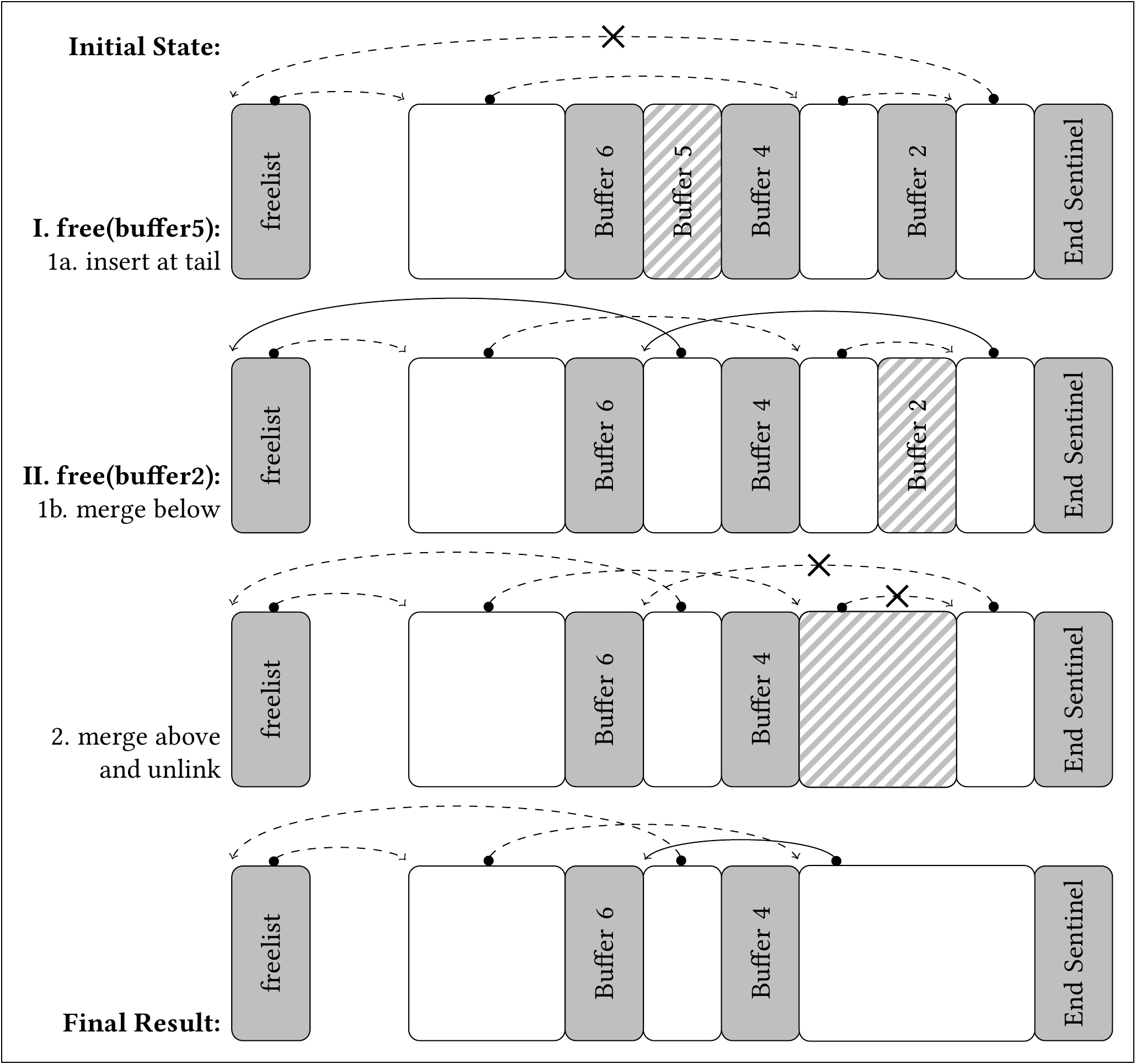 (Visualization of the change of the freelist during two free operations. Only forward links are shown. Solid arrows: Links newly created by the previous operation. Crosses: Links that will be overwritten after executing the next operation. Striped: Block to be processed by the current operation.)
(Visualization of the change of the freelist during two free operations. Only forward links are shown. Solid arrows: Links newly created by the previous operation. Crosses: Links that will be overwritten after executing the next operation. Striped: Block to be processed by the current operation.)
Merges with memory outside the assigned range is prevented by the initialization, marking the non-existent block below the first block as used by setting the prevfree field to zero, and by adding a block header at the end of the range, representing a used block, with a magic value as its size – which however is not checked against in the BGET configuration at hand.
Heap Prediction
This combination of allocation strategy and splitting mechanism causes the heap to initially behave like the stack, placing new buffers or data structures below the newest and lowest data structure currently in use – although with 16 bytes of overhead in between and at the boundaries of the available buffer. When predicting heap memory locations, reverse engineering can be used to identify TA-specific memory allocations.
Prior to the application’s allocations, the TA’s initialization process already requests 16 bytes for the malloc implementation wrapping BGET itself, 32 bytes for the initialization of the math API, and 32 bytes for every session opened to the TA, with 16 bytes of overhead each. You can find those by searching the code for any malloc, calloc or realloc calls, or with the GDB debugger. This results in an additional offset of 0x80 bytes from the heap’s upper boundary.
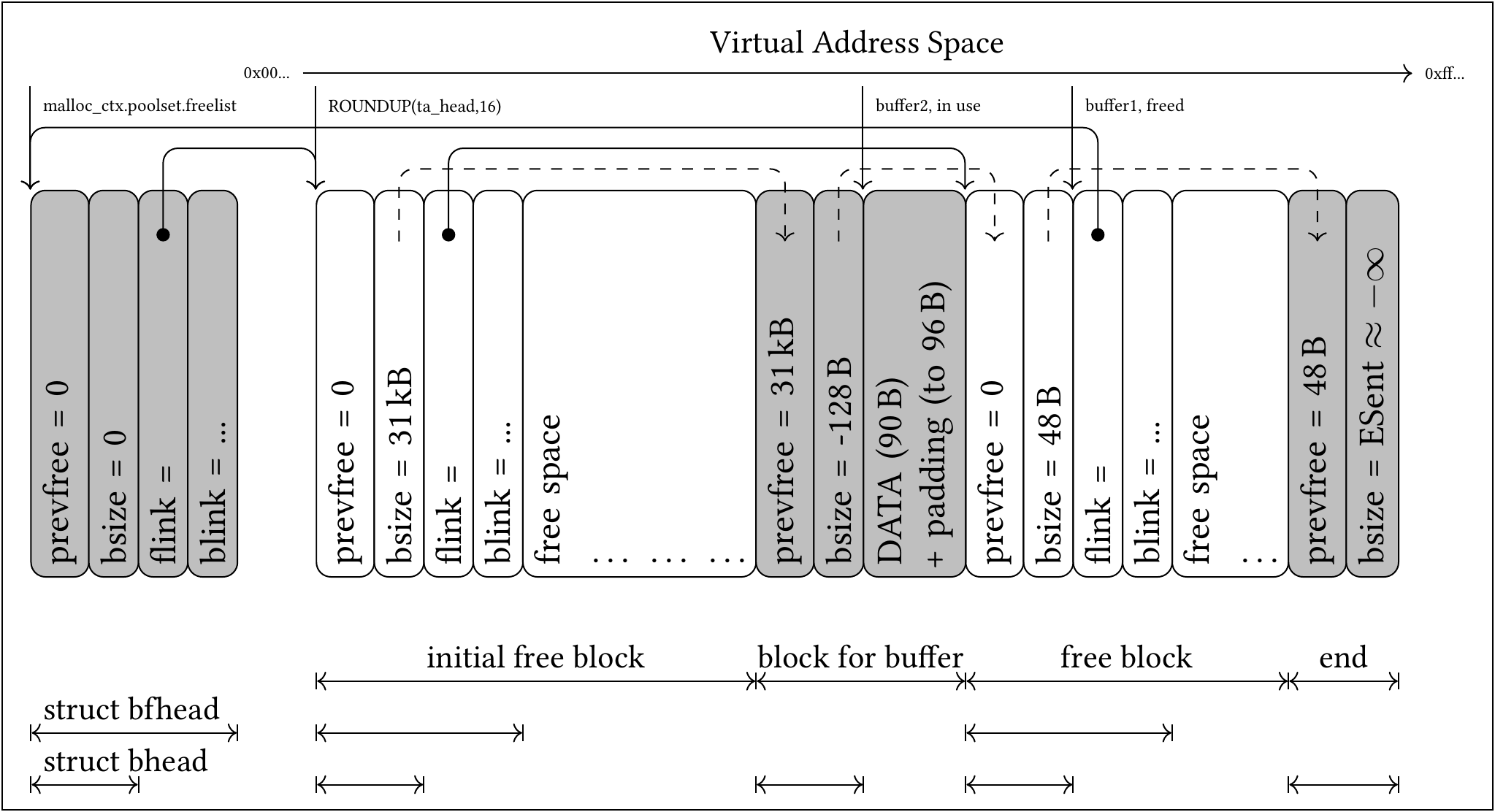 (Visualization of OP-TEE’s freelist root element and the BGET heap linked to by it, containing exemplary blocks. Gray: Blocks not available for allocation; White: Free Blocks available for allocation. Overview of the structs’ elements: prevfree is the size of the preceding block, if it is free, and roughly equals glibc’s prevsize element. bsize is the size of the current block, including its header, which is negated if the block is free. Free blocks additionally contain two pointers flink and blink, pointing forwards and backwards in the double linked freelist. Solid arrows represent pointers. Dashed Arrows point toward dependant values. On the bottom: Instances of the structs bhead and bfhead used by BGET.)
(Visualization of OP-TEE’s freelist root element and the BGET heap linked to by it, containing exemplary blocks. Gray: Blocks not available for allocation; White: Free Blocks available for allocation. Overview of the structs’ elements: prevfree is the size of the preceding block, if it is free, and roughly equals glibc’s prevsize element. bsize is the size of the current block, including its header, which is negated if the block is free. Free blocks additionally contain two pointers flink and blink, pointing forwards and backwards in the double linked freelist. Solid arrows represent pointers. Dashed Arrows point toward dependant values. On the bottom: Instances of the structs bhead and bfhead used by BGET.)
Further sources: optee_os sourcecode and GDB attached to an emulation within QEMU.
(tbc.)